Types of AWS databases
AWS provides multiple types of databases that can be split in to:
- SQL Databases (Serverless & Non-Serverless);
- No SQL Databases (Serverless & Non-Serverless);
What does "managed service" mean?
SQL Databases
Amazon RDS
RDS is a managed service for relational databases that supports standard SQL queries and automates provisioning, backups, patching and scaling.
Note: RDS has a feature called “RDS Auto Scaling” that enables auto scaling capabilities for RDS databases.
RDS supports PostgreSQL, MySQL, MariaDB, Oracle, Microsoft SQL Server, IBM DB2 and Aurora (AWS proprietary).
Note: We cannot SSH into RDS, unless using RDS custom, (Oracle & Microsoft SQL Server only.
RDS Replication
Replication is used to scale read traffic by creating read replicas of the primary DB.
Costs associated RDS with replication
It is possible to create up to 15 asynchronous read replicas, however, only the primary DB accepts writes.
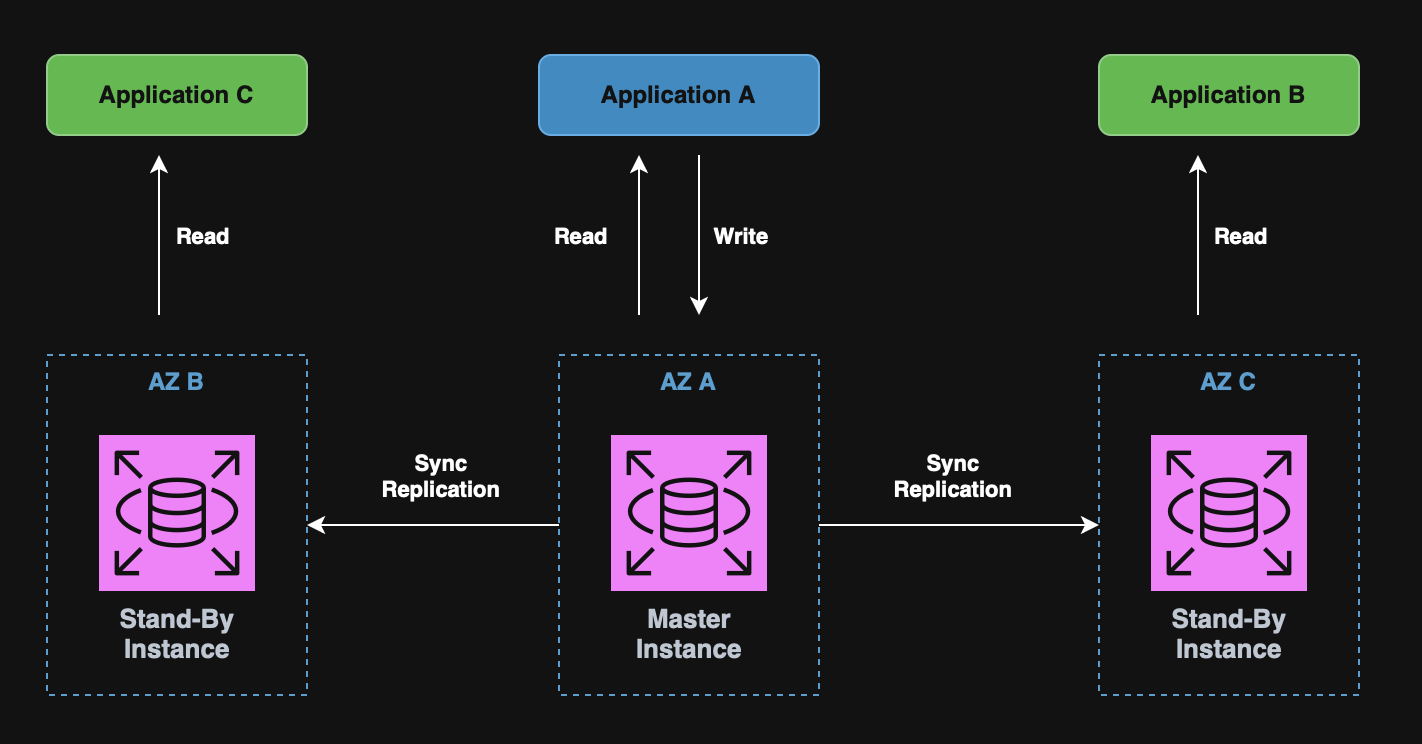
Note: Read replication is meant for performance increase, not disaster recovery! For the latter, use RDS Multi-AZ.
RDS Multi-AZ
RDS is able to setup instances of a database for disaster recovery reasons.
Can RDS read replicas be setup as multi-AZ for disater recovery?
Yes, they can.
These setups consist of stand-by instances, that are not used by any applications, until the primary instance has an outage.
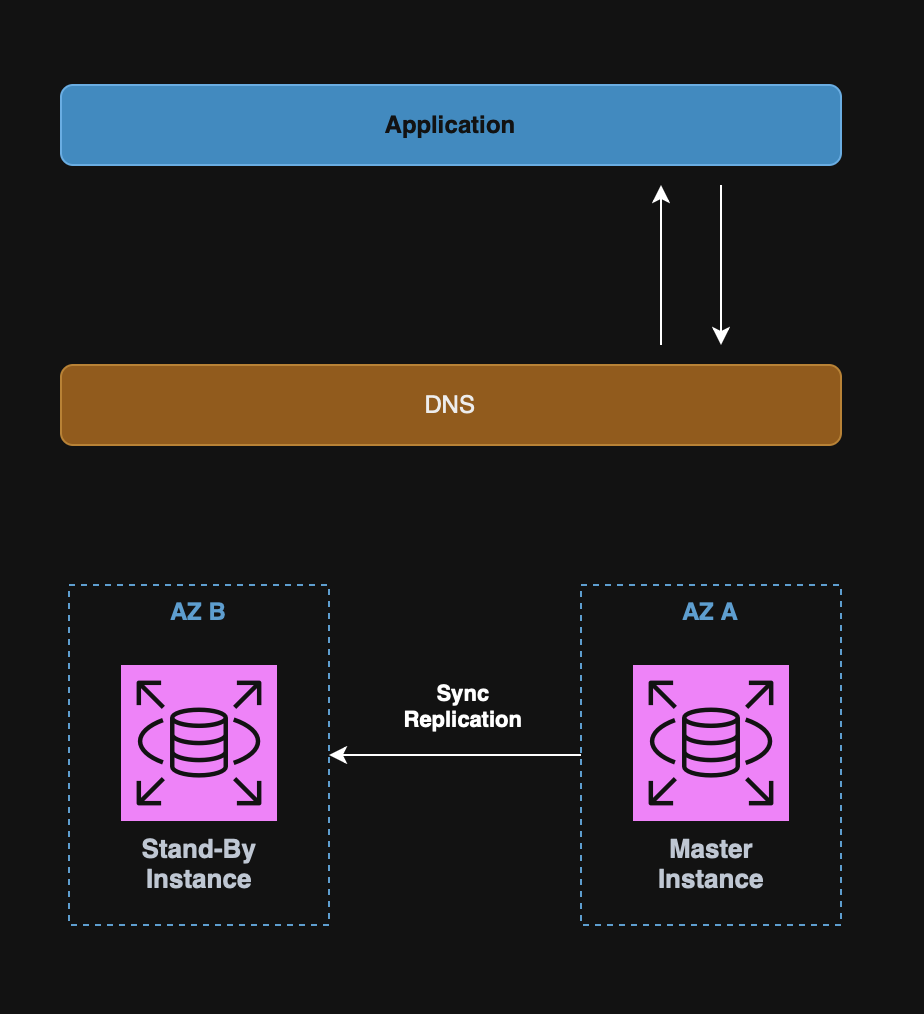
Note: Multi-AZ is used for increased availability, not auto scaling.
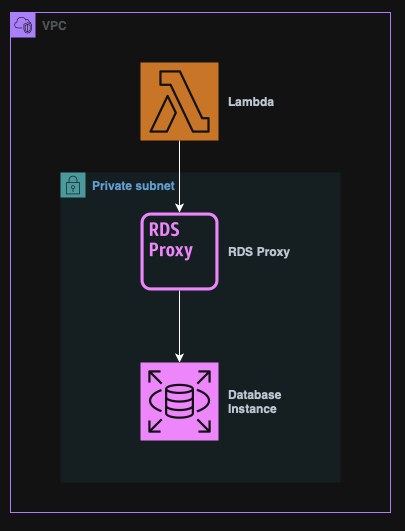
RDS Proxy
RDS Proxy is a fully managed, highly available database proxy service for RDS and Aurora.
It sits between an application and the database, managing connections and improving performance, availability and security.
Proxy accessibility
An RDS Proxy cannot be public, it must be accessed from inside a VPC.
RDS Proxy was designed to solve three main problems:
- Large numbers of database connections:
- Useful for applications or micro-services that can open thousands of connections without closing them.
- RDS Proxy pools and reuses connections so the database can work less and perform better.
- Improving database resiliency:
- When an RDS database fails over (e.g., Multi-AZ failover), applications may experience errors or timeouts.
- RDS Proxy can buffer and retry calls, drastically reducing downtime for apps.
- Centralizing and improving database security:
- It integrates with IAM authentication and AWS Secrets Manager to avoid hardcoded DB passwords and rotate secrets automatically.
Note: A proxy can reduce RDS & Aurora failover time by up to 66%.
Amazon Aurora (Serverless)
Aurora is a fully managed, MySQL & PostgreSQL compatible relational database engine designed for the cloud, combining high performance and availability.
Key points:
- Offers up to 5x the performance of a standard MySQL and 3x of PostgreSQL;
- Storage automatically scales in increments of 10 GB up to 128 TB;
- Costs more than RDS (~20%);
- Provides automated backups, snapshots and replication;
Aurora stores 6 copies of data across 3 different AZs, only needing 4 copies for writes and 3 for reads.
Note: Aurora has a auto scaling enabled for read replicas.
No SQL Databases
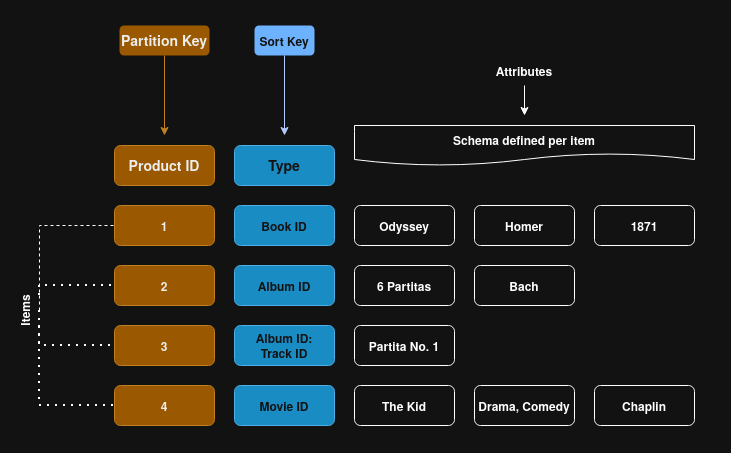
DynamoDB (Serverless)
DynamoDB is a fully managed, NoSQL database that offers single-digit millisecond latency and scales automatically.
Key points:
- Key-value & document data models;
- Supports millions of requests per second;
- Ideal for real time applications, IoT, gaming and mobile apps;
DynamoDB Accelerator (DAX)
DAX is a fully managed in-memory cache for DynamoDB that improves read performance by up to 10x.
Note: DAX is only for DynamoDB.
DocumentDB (Serverless)
DocumentDB is a fully managed MongoDB compatible database engine designed for the cloud, combining high performance and availability.
Amazon Neptune
Neptune is a fully managed graph database for storing complex relationships and querying them with high performance.
Use cases: Social networks, recommendation engines, fraud detection.
Note: Supports property graph (Gremlin) & RDF (SPARQL) models.
DMS - Database Migration Service
The AWS Database Migration Service helps migrating databases to AWS quickly and securely.
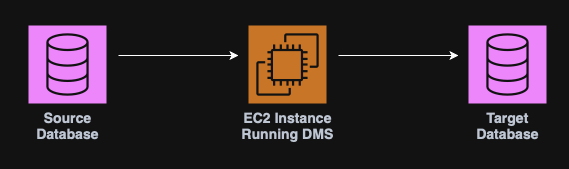
Key points:
- Supports homogeneous migrations, (e.g. Oracle to Oracle);
- Supports heterogeneous migrations (e.g. Microsoft SQL Server to Amazon Aurora);
- Minimal downtime during migration;
- Can migrate data continuously.
Amazon Quicksight
Amazon Quicksight is a serverless machine learning-powered business intelligence service to create interactive dashboards.
Amazon ElastiCache
Amazon ElastiCache is a fully managed service that allows you to deploy, operate, and scale in-memory data stores like Redis and Memcached.
It is specifically designed for high performance and low latency.
Use cases: Caching, real-time analytics, session stores and leaderboards.
When to use Redis and Memcached?
Redis provides high availability, memcached does not; Redis provides persistent data, Memcached does not; Both provide backup & restore features. (Memcached serverless only). In general, Redis is always the better option, unless the architecture requires multi-threading.
Amazon Redshift
Amazon Redshift is designed for analytics and reporting on large volumes of structured and semi-structured data.
Redshift stores data columnar (column-oriented), which is optimized for aggregations and analytical queries rather than transactional workloads.
Amazon EMR
Amazon EMR is a managed big data processing service. It allows the processing and analysis on massive amounts of data using frameworks like Apache Hadoop, Spark, HBase, Flink, and Presto.
EMR takes care of provisioning and configuring multiple EC2 instances in a cluster so that they can work together in analyzing data from a big data perspective.
Use cases: Data processing, machine learning, web indexing, big data, etc.